class: center, middle, inverse, title-slide # Analysis of Unstructured Text ## SSC Data Science and Analytics Workshop ### Nathan Taback ### Statistical Sciences and Computer Science, University of Toronto ### June 4, 2020 --- # Outline - R Libraries for Working with Text - Importing unstructured text into R: copy/paste, external API, webscraping, R libraries - Regular expressions and text normalization (e.g., tokenization) - N-Grams - Word Vectors and Matricies --- class: center, middle # Introduction --- # Example 1: Trump's Letter to WHO .pull-left[ ] .pull-right[ - [Donald Trump's letter](<https://www.whitehouse.gov/wp-content/uploads/2020/05/Tedros-Letter.pdf>) to the Director General of the World Health Organization, Dr. Tedros, is an example of unstructured data. - There are dates, numbers, and text that does not have a pre-defined data structure.] --- ## Example 2: Analysis of p-values .pull-left[ ] .pull-right[ >.small[ We defined a P value report as a string starting with either “p,” “P,” “p-value(s),” “P-value(s),” “P value(s),” or “p value(s),” followed by an equality or inequality expression (any combination of =, <, >, ≤, ≥, “less than,” or “of <” and then by a value, which could include also exponential notation (for example, 10-4, 10(-4), E-4, (-4), or e-4).] ] .midi[p-values were extracted from papers using a regular expression] --- # Programming Languages for Working With Unstructured Text - Two popular languages for computing with data are R and Python. - We chose R for this workshop, but we could have selected Python. --- ## R Libraries for Working with Text Some very useful R libraries for working with unstructured text that are used in this workshop: - `base` - `tidyverse` - `janitor` - `tidytext` - `rvest` - `RSelenium` --- class: center, middle # Importing text into R --- ## Copy/Paste .pull-left[- For one-time this can work well. 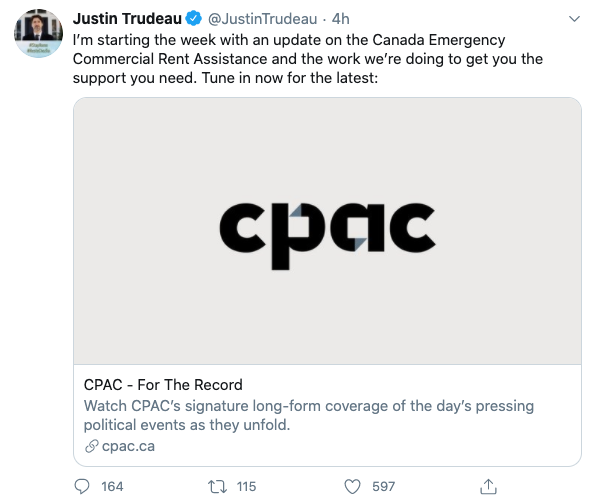] .pull-right[.small[ ```r tweet_txt <- "I’m starting the week with an update on the Canada Emergency Commercial Rent Assistance and the work we’re doing to get you the support you need. Tune in now for the latest:" tweet_link <- "https://www.cpac.ca/en/programs/covid-19-canada-responds/episodes/66204762/" tweet_replies <- 164 tweet_rt <- 116 tweet_likes <- 599 tweet_url <- "https://twitter.com/JustinTrudeau/status/1264939872055431168?s=20" ``` ] ] .question[How many words in the tweet text?] --- ```r library(tidyverse) ``` ``` ## ── Attaching packages ─────────────────────────────────── tidyverse 1.3.0 ── ``` ``` ## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4 ## ✓ tibble 3.0.1 ✓ dplyr 1.0.0 ## ✓ tidyr 1.1.0 ✓ stringr 1.4.0 ## ✓ readr 1.3.1 ✓ forcats 0.5.0 ``` ``` ## ── Conflicts ────────────────────────────────────── tidyverse_conflicts() ── ## x dplyr::filter() masks stats::filter() ## x dplyr::lag() masks stats::lag() ``` --- ## Tokenization .small[ ```r library(tidytext) # a data frame (tibble) that separates the text into words and stores # the result in a tibble column called out tibble(tweet_txt) %>% unnest_tokens(out, tweet_txt, token = "words") ``` ``` ## # A tibble: 32 x 1 ## out ## <chr> ## 1 i’m ## 2 starting ## 3 the ## 4 week ## 5 with ## 6 an ## 7 update ## 8 on ## 9 the ## 10 canada ## # … with 22 more rows ``` ```r # count the number of words use summarise with n() tibble(tweet_txt) %>% unnest_tokens(out, tweet_txt, token = "words") %>% summarise(Num_words = n()) ``` ``` ## # A tibble: 1 x 1 ## Num_words ## <int> ## 1 32 ``` ] --- # Brief `tidyverse` detour - A tibble is the `tidyverse` version of a data frame, and in most use-cases the two can be used interchangeably. - The `%>%` is similar to function composition: `\((f \circ g \circ h) (x)\)` is analagous to ` x %>% h() %>% g() %>% f()` --- # Brief `tidyverse` detour ```r summarise(unnest_tokens(tibble(tweet_txt), out, tweet_txt, token = "words"), Num_words = n()) ``` is the same as ```r tibble(tweet_txt) %>% unnest_tokens(out, tweet_txt, token = "words") %>% summarise(Num_words = n()) ``` We could have done the same using base `R` functions: ```r length(unlist(strsplit(tweet_txt, split = " "))) ``` --- # Brief `tidyverse` detour In the "tidy tools manifesto" (see vignettes in `tidyverse`) Hadley Wickham states tht there are four basic principles to a tidy API: - Reuse existing data structures. -- - Compose simple functions with the pipe `%>%`. -- - Embrace functional programming. -- - Design for humans. --- ## Using an External API to Access Data R has several libraries where the objective is to import data into R from an external website such as twitter or PubMed. --- ## `rtweet` Twitter has an API that can be accessed via the R library `rtweet`. ```r library(rtweet) * source("twitter_creds.R") token <- create_token( app = "nlpandstats", consumer_key = api_key, consumer_secret = api_secret_key) ``` see rtweet [article](https://rtweet.info/articles/auth.html) on tokens. --- ```r # read csv file JTtw <- rtweet::read_twitter_csv("JT20tweets_may25.csv") ``` Count the number of words in each tweet. ```r # index each tweet with rowid then count # rowids rowid_to_column(JTtw) %>% unnest_tokens(out, text, token = "words") %>% count(rowid) %>% head() ``` ``` ## # A tibble: 6 x 2 ## rowid n ## <int> <int> ## 1 1 42 ## 2 2 47 ## 3 3 30 ## 4 4 42 ## 5 5 38 ## 6 6 44 ``` --- Plot the distribution of word counts in JT's tweets. .left-code[ .small[ ```r # index each tweet with rowid # then count rowids text_counts <- rowid_to_column(JTtw) %>% unnest_tokens(out, text, token = "words") %>% count(rowid) ``` ```r text_counts %>% ggplot(aes(n)) + geom_histogram(bins = 5, colour = "black", fill = "grey") + xlab("Number of Words") + ggtitle("Number of Words in 20 Trudeau Tweets") + theme_classic() ``` ] ] .right-plot[ <img src="workshopslides1_files/figure-html/unnamed-chunk-11-1.png" width="80%" /> ] --- What about the relationship between retweet count and word count? .left-code[ .small[ ```r #merge original data frame to data # frame with counts by rowid rowid_to_column(JTtw) %>% left_join(text_counts, by = "rowid") %>% select(rowid, n, retweet_count) %>% ggplot(aes(n, log10(retweet_count))) + geom_point() + xlab("Number of Words") + ylab("log of retweet count") + ggtitle("Retweet Count versus Number of Words in 20 Trudeau Tweets") + theme_classic() ``` ] ] .right-plot[ <img src="workshopslides1_files/figure-html/unnamed-chunk-12-1.png" width="80%" /> ] --- Twitter [suggests](https://business.twitter.com/en/blog/the-dos-and-donts-of-hashtags.html) that hashtags use all caps. ```r JTtw$hashtags ``` ``` ## [1] "PKDay" "PKDay" NA NA ## [5] NA NA NA NA ## [9] NA NA NA NA ## [13] NA NA "COVID19" "COVID19" ## [17] NA NA "GlobalGoalUnite" "GlobalGoalUnite" ``` ```r # check if hastags are all upper case then count the number sum(toupper(JTtw$hashtags) == JTtw$hashtags, na.rm = TRUE) ``` ``` ## [1] 2 ``` ```r length(JTtw$hashtags) ``` ``` ## [1] 20 ``` ```r sum(toupper(JTtw$hashtags) == JTtw$hashtags, na.rm = TRUE)/length(JTtw$hashtags) ``` ``` ## [1] 0.1 ``` --- # R Libraries with Unstructured Text There are many R libraries with unstructured text available. A few examples include: [`geniusr`](https://ewenme.github.io/geniusr/articles/geniusr.html) for song lyrics, and [`gutenbergr`](https://github.com/ropensci/gutenbergr) for lit. --- ## `gutenbergr` - Project Gutenberg is a free library of mostly older literary works (e.g., Plato and Jane Austen), although there are several non-literary works. There are over 60,000 books. - `gutenbergr` is a package to help download and process these works. ```r library(gutenbergr) gutenberg_works(str_detect(author, "Einstein")) ``` ``` ## # A tibble: 2 x 8 ## gutenberg_id title author gutenberg_autho… language gutenberg_books… rights ## <int> <chr> <chr> <int> <chr> <chr> <chr> ## 1 5001 Rela… Einst… 1630 en Physics Publi… ## 2 7333 Side… Einst… 1630 en <NA> Publi… ## # … with 1 more variable: has_text <lgl> ``` ```r einstein_talk <- gutenberg_download(7333) ``` --- .left-code[ .small[ ```r einstein_talk %>% unnest_tokens(out, text) %>% count(out) %>% top_n(20) %>% ggplot(aes(reorder(out,-n), n)) + geom_col() + xlab("word") + ylab("Frequency") ``` ] ] .right-plot[ <img src="workshopslides1_files/figure-html/unnamed-chunk-15-1.png" width="80%" /> ] --- Let's remove stop words such as "the" and "it". `stop_words` is a dataframe of stop words in `tidytext`. .left-code[ .small[ ```r stop_words %>% head() ``` ``` ## # A tibble: 6 x 2 ## word lexicon ## <chr> <chr> ## 1 a SMART ## 2 a's SMART ## 3 able SMART ## 4 about SMART ## 5 above SMART ## 6 according SMART ``` ```r einstein_talk %>% unnest_tokens(out, text) %>% anti_join(stop_words, by = c("out" = "word")) %>% count(out) %>% top_n(20) %>% ggplot(aes(reorder(out,-n), n)) + geom_col() + xlab("word") + ylab("Frequency") + theme_classic() + theme(axis.text.x = element_text(angle = 45, vjust=0.5)) ``` ] ] .right-plot[ <img src="workshopslides1_files/figure-html/unnamed-chunk-17-1.png" width="80%" /> ] --- class: center, middle # Web scraping --- - The Stanford Encyclopedia of Philosophy (SEP) is a "dynamic reference work [that] maintains academic standards while evolving and adapting in response to new research" on philosophical topics. "Entries should focus on the philosophical issues and arguments rather than on sociology and individuals, particularly in discussions of topics in contemporary philosophy. In other words, entries should be "idea-driven" rather than "person-driven". - Which philosophers appear most frequently in SEP entries? A list of philosopehrs can be obtained by scraping a few Wikipedia pages using `rvest`. --- The basic idea is to inspect the page and figure out which part of the page contains the information you want. - Start by inspecting the element of this [Wikipedia page](https://en.wikipedia.org/wiki/List_of_philosophers_(A%E2%80%93C) 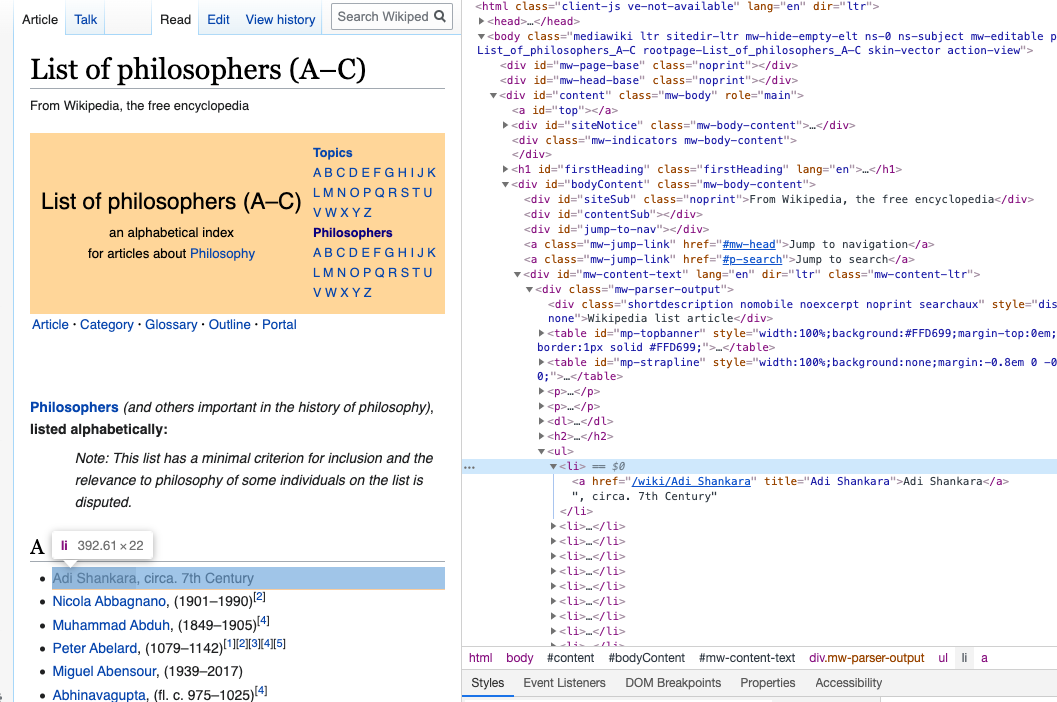 --- - The names are stored in an html unordered list `<ul>` as items `<li>`. So, extract these nodes using `html_nodes()` then extract the text using `html_text()`.  --- <img src="phil_screenshot.png" width="600" height="300"> .small[ ```r library(rvest) # read the webpage ac_url <- "https://en.wikipedia.org/wiki/List_of_philosophers_(A%E2%80%93C)" wiki_philnamesAC <- xml2::read_html(ac_url) wiki_philnamesAC %>% html_nodes("div.mw-parser-output ul li") %>% html_text() %>% head() ``` ``` ## [1] "Article" "Category" ## [3] "Glossary" "Outline" ## [5] "Portal" "Adi Shankara, circa. 7th Century" ``` ] Remove the the first 5 rows using `slice(-(1:5))`. --- Write a function to do this for the four Wikipedia pages .small[ ```r getphilnames <- function(url, removerows){ philnames <- xml2::read_html(url) %>% html_nodes("div.mw-parser-output ul li") %>% html_text() %>% tibble(names = .) %>% # rename the column name slice(removerows) return(philnames) } ``` ```r names_ac <- getphilnames("https://en.wikipedia.org/wiki/List_of_philosophers_(A%E2%80%93C)", -(1:5)) names_dh <- getphilnames("https://en.wikipedia.org/wiki/List_of_philosophers_(D%E2%80%93H)", -(1:5)) names_iq <- getphilnames("https://en.wikipedia.org/wiki/List_of_philosophers_(I%E2%80%93Q)", -(1:5)) names_rz <- getphilnames("https://en.wikipedia.org/wiki/List_of_philosophers_(R%E2%80%93Z)", -(1:5)) *wiki_names <- rbind(names_ac, names_dh, names_iq, names_rz) wiki_names %>% head() ``` ``` ## # A tibble: 6 x 1 ## names ## <chr> ## 1 Adi Shankara, circa. 7th Century ## 2 Nicola Abbagnano, (1901–1990)[2] ## 3 Muhammad Abduh, (1849–1905)[4] ## 4 Peter Abelard, (1079–1142)[1][2][3][4][5] ## 5 Miguel Abensour, (1939–2017) ## 6 Abhinavagupta, (fl. c. 975–1025)[4] ``` ] --- - We need to extract the names from each entry. This is the same as removing all the text after the comma. - The regular expression `,.*$` matches all text after (and including) the comma then we can remove is with `str_remove()` (`str_remove()` is vectorized). ```r # the regex ,.*$ matches , and any letter . until # the end $ of the string # str_remove() removes the matches *wiki_names <- str_remove(wiki_names$names, ",.*$") wiki_names %>% head() ``` ``` ## [1] "Adi Shankara" "Nicola Abbagnano" "Muhammad Abduh" "Peter Abelard" ## [5] "Miguel Abensour" "Abhinavagupta" ``` --- We can use tools in the [`RSelenium`](https://docs.ropensci.org/RSelenium/) library to automate (via programming) web browsing. It is primarily used for testing webapps and webpages across a range of browser/OS combinations. To run the Selenium Server I'll run the [Docker](https://www.docker.com/) container .small[ ```zsh docker run -d -p 4445:4444 selenium/standalone-firefox:2.53.1 ``` ```r library(RSelenium) # connect to server remDr <- remoteDriver( remoteServerAddr = "localhost", port = 4445L, browserName = "firefox" ) # connect to the server remDr$open() #Navigate to <https://plato.stanford.edu/index.html> remDr$navigate("https://plato.stanford.edu/index.html") # find search button webelem <-remDr$findElement(using = "id", value = "search-text") # input first philosophers name into search webelem$sendKeysToElement(list(wiki_names[1])) # find the search button button_element <- remDr$findElement(using = 'class', value = "icon-search") # click the search button button_element$clickElement() ``` ] --- There are 17 entries where Adi Shankara is found. 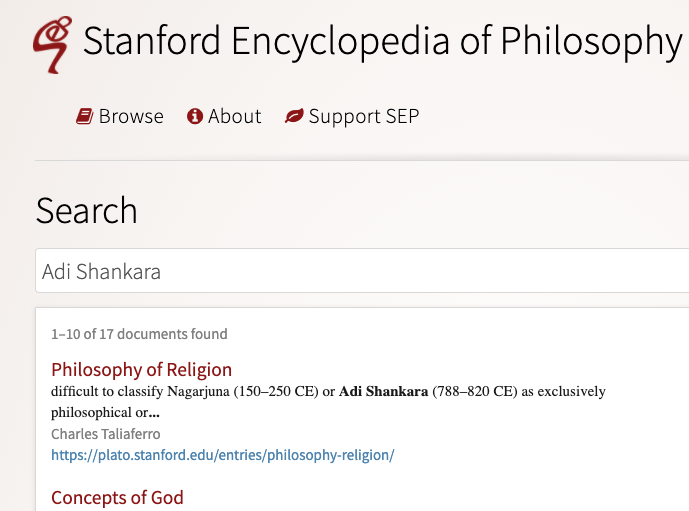 --- # robots.txt and Web scraping - The [robots.txt](https://en.wikipedia.org/wiki/Robots_exclusion_standard) file for SEP <https://plato.stanford.edu/robots.txt> disallows /search/. - This is usually disallowed to prevent [web crawlers](https://en.wikipedia.org/wiki/Web_crawler) from linking to the SEP search engine. - I contacted the editor of SEP and was given permission to include this example as part of this workshop. - "... ethical questions surrounding web scraping, or the practice of large scale data retrieval over the Internet, will require humanists to frame their research to distinguish it from commercial and malicious activities."[(Michael Black, 2016)](https://www.euppublishing.com/doi/full/10.3366/ijhac.2016.0162) --- How can we extract 17 from the webpage? Let's inspect the element that corresponds to 17. <img src="inspect_total.png" width="600" height="250"> Find the element related to `search_total` then extract the text. .small[ ```r # find element out <- remDr$findElement(using = "class", value="search_total") # extract text tot <- out$getElementText() tot ``` ``` ## [[1]] ## [1] "1–10 of 17 documents found" ``` ] --- Now, use a regular expression to extract the number just before documents. ```r # extract the number of dicuments str_extract(tot[[1]],"\\d+(?= documents)") ``` ``` ## [1] "17" ``` ```r # show the match str_view_all(tot[[1]],"\\d+(?= documents)") ``` <div id="htmlwidget-2dc284904b6d68702d66" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-2dc284904b6d68702d66">{"x":{"html":"<ul>\n <li>1–10 of <span class='match'>17<\/span> documents found<\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- Now create a function to do this so that we can interate. It's good practice to add a delay using `Sys.sleep()` so that we don't stretch the SEP server capacity. ```r getcount <- function(i){ Sys.sleep(0.05) remDr$navigate("https://plato.stanford.edu/index.html") webelem <-remDr$findElement(using = "id", value = "search-text") webelem$sendKeysToElement(list(wiki_names[i])) button_element <- remDr$findElement(using = 'class', value = "icon-search") button_element$clickElement() out <- remDr$findElement(using = "class", value="search_total") tot <- out$getElementText() str_view_all(tot[[1]],"\\d+(?= documents)") tot <- str_extract(tot[[1]],"\\d+(?= documents)") return(as.numeric(tot)) } ``` --- .left-code[ .small[ ```r # Let's look at the first 10 names # tidyverse approach # in base R could use # sapply(1:10, getcount, simplify = TRUE) counts <- 1:10 %>% map(getcount) %>% flatten_dbl() tibble(names = wiki_names[1:10], counts) %>% drop_na() %>% ggplot(aes(reorder(names,counts), counts)) + geom_col() + coord_flip() + theme_classic() + ylab("Number of entries") + xlab("Philosopher") ``` ] ] .right-plot[ <img src="workshopslides1_files/figure-html/unnamed-chunk-28-1.png" width="80%" /> ] --- class: center, middle # Regular Expressions A formal language for specifying text strings. .pull-left[ .left[How can we search for any of these?] .left[ - cat - cats - Cat - Cats] ] .pull-right[  ] --- ## Regular Expressions: Characters - In R `\\` represents `\` - `\w` matches any word and `\W` matches any non-word characters such as `.` So to use this as a regular expression ```r str_view_all("Do you agree that stats is popular?", "\\w") ``` <div id="htmlwidget-2e3ca4a3b64346b652f9" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-2e3ca4a3b64346b652f9">{"x":{"html":"<ul>\n <li><span class='match'>D<\/span><span class='match'>o<\/span> <span class='match'>y<\/span><span class='match'>o<\/span><span class='match'>u<\/span> <span class='match'>a<\/span><span class='match'>g<\/span><span class='match'>r<\/span><span class='match'>e<\/span><span class='match'>e<\/span> <span class='match'>t<\/span><span class='match'>h<\/span><span class='match'>a<\/span><span class='match'>t<\/span> <span class='match'>s<\/span><span class='match'>t<\/span><span class='match'>a<\/span><span class='match'>t<\/span><span class='match'>s<\/span> <span class='match'>i<\/span><span class='match'>s<\/span> <span class='match'>p<\/span><span class='match'>o<\/span><span class='match'>p<\/span><span class='match'>u<\/span><span class='match'>l<\/span><span class='match'>a<\/span><span class='match'>r<\/span>?<\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- - `\d` matches any digit, - `\D` matches any non-digit, - `.` matches every character except new line. - `\s` matches any whitespace ```r str_view_all("There are at least 200 people in this zoom!", "\\d") ``` <div id="htmlwidget-c5791a8c3cacc23db6ee" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-c5791a8c3cacc23db6ee">{"x":{"html":"<ul>\n <li>There are at least <span class='match'>2<\/span><span class='match'>0<\/span><span class='match'>0<\/span> people in this zoom!<\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- # Regular Expressions: Alternates (Disjunctions) - Letters inside square brackets `[]` or use pipe `|`. ```r # tidyverse style str_view_all(string = c("cat","Cat"), pattern = "[cC]") # match c or C ``` <div id="htmlwidget-56feb0fb8d66d8686f22" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-56feb0fb8d66d8686f22">{"x":{"html":"<ul>\n <li><span class='match'>c<\/span>at<\/li>\n <li><span class='match'>C<\/span>at<\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- # Regular Expressions: Alternates (Disjunctions) - Ranges `[A-Z]`, `[a-z]`, `[0-9]`, `[:digit:]`, `[:alpha:]` ```r str_view(string = c("cat","Cat 900"), pattern = "[0-9]") # first match of any digit ``` <div id="htmlwidget-ab73a044b7b5ad9d07fd" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-ab73a044b7b5ad9d07fd">{"x":{"html":"<ul>\n <li>cat<\/li>\n <li>Cat <span class='match'>9<\/span>00<\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- - Negations in disjunction `[^A]`. - When `^` is first in `[]` it means negation. For example, `[^xyz]` means neither `x` nor `y` nor `z`. ```r str_view_all(string = c("xenophobia causes problems"), pattern = "[^cxp]") # neither c nor x nor p ``` <div id="htmlwidget-c6983a8a05f265063048" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-c6983a8a05f265063048">{"x":{"html":"<ul>\n <li>x<span class='match'>e<\/span><span class='match'>n<\/span><span class='match'>o<\/span>p<span class='match'>h<\/span><span class='match'>o<\/span><span class='match'>b<\/span><span class='match'>i<\/span><span class='match'>a<\/span><span class='match'> <\/span>c<span class='match'>a<\/span><span class='match'>u<\/span><span class='match'>s<\/span><span class='match'>e<\/span><span class='match'>s<\/span><span class='match'> <\/span>p<span class='match'>r<\/span><span class='match'>o<\/span><span class='match'>b<\/span><span class='match'>l<\/span><span class='match'>e<\/span><span class='match'>m<\/span><span class='match'>s<\/span><\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- # Regular Expressions: Anchors - `^a` matches `a` at the start of a string and `a$` matches `a` at the end of a string. ```r str <- c("xenophobia causes problems", "Xenophobia causes problems") # x at the beginning or s at the end of string str_view_all(string = str, pattern = "^x|s$") ``` <div id="htmlwidget-530aef1c5f5f829fca43" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-530aef1c5f5f829fca43">{"x":{"html":"<ul>\n <li><span class='match'>x<\/span>enophobia causes problem<span class='match'>s<\/span><\/li>\n <li>Xenophobia causes problem<span class='match'>s<\/span><\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- # Regular Expressions: Quantifiers - `a?` matches exactly zero or one `a` - `a*` matches zero or more `a` - `a+` matches one or more `a` - `a{3}` matches exactly 3 `a`'s ```r str_view_all(string = c("colour","color","colouur"), pattern = "colou+r") ``` <div id="htmlwidget-98d6b188138c34f969df" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-98d6b188138c34f969df">{"x":{"html":"<ul>\n <li><span class='match'>colour<\/span><\/li>\n <li>color<\/li>\n <li><span class='match'>colouur<\/span><\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- # Regular Expressions: Groups/Precedence - How can I specify both puppy and puppies? ```r # disjuction only applies to suffixes y and ies str_view_all(string = c("puppy", "puppies"), pattern = "pupp(y|ies)") ``` <div id="htmlwidget-dcd74af36c9148655e41" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-dcd74af36c9148655e41">{"x":{"html":"<ul>\n <li><span class='match'>puppy<\/span><\/li>\n <li><span class='match'>puppies<\/span><\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> --- # Example from p-value paper  A p-value in an article was defined as: > We defined a P value report as a string starting with either “p,” “P,” “p-value(s),” “P-value(s),” “P value(s),” or “p value(s),” followed by an equality or inequality expression (any combination of =, <, >, ≤, ≥, “less than,” or “of <” and then by a value, which could include also exponential notation (for example, 10-4, 10(-4), E-4, (-4), or e-4). --- Let's look at extracting all the variations of *p value* from a few sentences using the regular expression provided in the appendix of Chavalarias et al. (2016). ```r "/(\s|\()[Pp]{1}(\s|-)*(value|values)?(\s)*([=<>≤≥]|less than|of<)+(\s)*([0-9]|([\,|\.|•][0-9]))[0-9]*[\,|\.|•]?[0-9]*(\s)*((\%)|([x|×]?(\s)*[0-9]*(\s)*((exp|Exp|E|e)?(\s)*((\((\s)*(-){1}(\s)*[0-9]+(\s)*\))|((\s)*(-){1}(\s)*[0-9]+)))?))/" ``` Namely, ```r (\s|\()[Pp]{1}(\s|-)*(value|values)?(\s) ``` - `(\s|\()` whitespace or `(` - `[Pp]{1}` Match either `P` or `p` exactly once - `(\s|-)*` whitespace or `-` zero or more times - `(value|values)?` zero or one times - `(\s)` whitespace --- .small[ ```r str <- c("The result was significant (p < ", "The result was significant P = ", "The result was not significant p-value(s) less than ", "The result was significant P-value(s) ≤ ", "The result was significant P value(s) < ", "The result was significant p value(s) < ") ppat <- "(\\s|\\()[Pp]{1}(\\s|-)*(value|values)?(\\s)" str_view_all(str, pattern = ppat) ``` <div id="htmlwidget-cbdfc3bfe857757b5262" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-cbdfc3bfe857757b5262">{"x":{"html":"<ul>\n <li>The result was significant <span class='match'>(p <\/span>< <\/li>\n <li>The result was significant<span class='match'> P <\/span>= <\/li>\n <li>The result was not significant p-value(s) less than <\/li>\n <li>The result was significant P-value(s) ≤ <\/li>\n <li>The result was significant<span class='match'> P <\/span>value(s) < <\/li>\n <li>The result was significant<span class='match'> p <\/span>value(s) < <\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> ] But this doesn't capture "p value(s)". Is there a mistake in the data extraction? <br> .question[What should be added to the regular expression?] --- ```r ppat <- "(\\s|\\()[Pp]{1}(\\s|-)*(value|values|value\\(s\\))?(\\s)" str_view_all(str, pattern = ppat) ``` <div id="htmlwidget-ecea804fec8ddb0131ac" style="width:960px;height:100%;" class="str_view html-widget"></div> <script type="application/json" data-for="htmlwidget-ecea804fec8ddb0131ac">{"x":{"html":"<ul>\n <li>The result was significant <span class='match'>(p <\/span>< <\/li>\n <li>The result was significant<span class='match'> P <\/span>= <\/li>\n <li>The result was not significant<span class='match'> p-value(s) <\/span>less than <\/li>\n <li>The result was significant<span class='match'> P-value(s) <\/span>≤ <\/li>\n <li>The result was significant<span class='match'> P value(s) <\/span>< <\/li>\n <li>The result was significant<span class='match'> p value(s) <\/span>< <\/li>\n<\/ul>"},"evals":[],"jsHooks":[]}</script> <https://regex101.com/> is also helpful for visualizing regular expressions. --- # N-Grams - Models that assign probabilities to sequences of words are called language models. - An n-gram is a sequence of n words. - A 1-gram or unigram is one word sequence. - A 2-gram or bigram is a two word sequence. - A 3-gram or trigram is a three word sequence --- - Suppose we want to compute the probability of a word `\(W\)` given some history `\(H\)`, `\(P(W|H)\)` -- - The sentence "He had successfully avoided meeting his landlady ..." is at the beginning of Crime and Punishment by Fyodor Dostoevsky. -- - Let `\(h = \text{``He had successfully avoided meeting his''}\)` and `\(w = \text{``landlady''}\)`: Estimate using the relative frequency of counts: `$$\frac{\# \text{ ``He had successfully avoided meeting his landlady''}}{\# \text{ ``He had successfully avoided meeting his''}}$$` -- - This could be estimated using counts from searching the web using, say, Google. -- - But, new sentences are created all the time so it's difficult to estimate. --- - If we want to know the joint probability of an entire sequence of words like "He had successfully avoided meeting his" “out of all possible sequences of six words, how many of them are, "He had successfully avoided meeting his"? -- `$$P(\text{landlady}|\text{He had successfully avoided meeting his})$$` -- `$$P(X_7=\text{``landlady''}|X_1=\text{``He"}, X_2=\text{``had"}, \\ X_3=\text{``successfully"},\ldots, X_6=\text{``his"})$$` -- The bigram model approximates this probability using the Markov assumption. `$$P(X_7=\text{``landlady''}|X_1=\text{``He"}, X_2=\text{``had"}, \\ X_3=\text{``successfully"},\ldots, \\X_6=\text{``his"}) \approx \\ P(X_7=\text{``landlady''}|X_6=\text{``his"})$$` How can this be computed? --- - `\(C_{\text{his landlady}} =\)` count the number of bigrams that are "his landlady" -- - `\(C_{\text{his ...}} =\)` count the number of bigrams that have first word "his" -- - `\(C_{\text{his landlady}}/C_{\text{his ...}}\)` -- Compute the probability of the bigram "his landlady" in Crime and Punishment. .small[ ```r crimeandpun <- gutenberg_download(gutenberg_id = 2554) %>% slice(-(1:108)) # remove preface, etc. crimeandpun %>% unnest_ngrams(output = out, input = text, n = 2) %>% mutate(out = tolower(out), bigram_xy = str_detect(out, "his landlady"), # Boolean for his landlady bigram_x = str_detect(out, "^his")) %>% # Boolean for his ... filter(bigram_x == TRUE) %>% group_by(bigram_xy) %>% count() %>% # creates the variable n for each group ungroup() %>% # ungroup so we can sum n's in each group mutate(tot = sum(n), percent=round(n/tot,3)) ``` ``` ## # A tibble: 2 x 4 ## bigram_xy n tot percent ## <lgl> <int> <int> <dbl> ## 1 FALSE 2090 2100 0.995 ## 2 TRUE 10 2100 0.005 ``` ] --- # Word Vectors and Matrices - Words that occur in similar contexts tend to have similar meanings. The idea is that "a word is characterized by the company it keeps" (Firth, 1957). -- - For example, *oculist* and *eye doctor* tended to occur near words like *eye* or *examined*. -- - This link between similarity in how words are distributed and similarity in what they mean is called the **distributional hypothesis**. -- - A computational model that deals with different aspects of word meaning is to define a word as a vector in `\(N\)` dimensional space, although the vector can be defined in different ways. --- # Term Document Matrix .pull-left[ .small[ .left[How often do the the words (term), battle, good, fool, and wit occur in a particular Shakespeare play (document)?] ```r library(janitor) AsYouLikeIt <- gutenberg_download(1523) %>% add_column(book = "AsYouLikeIt") %>% slice(-c(1:40)) TwelfthNight <- gutenberg_download(1526) %>% add_column(book = "TwelfthNight") %>% slice(-c(1:31)) JuliusCaesar <- gutenberg_download(1785) %>% add_column(book = "JuliusCaesar") %>% slice(-c(1:291)) HenryV <- gutenberg_download(2253) %>% add_column(book = "HenryV") %>% slice(-c(1:94)) shakespeare_books <- rbind(AsYouLikeIt,TwelfthNight, JuliusCaesar, HenryV) shakespeare_books %>% unnest_tokens(out, text) %>% mutate(out = tolower(out)) %>% filter(out == "battle"|out == "good" | out == "fool"|out == "wit") %>% group_by(book, out) %>% tabyl(out, book) %>% knitr::kable() %>% kableExtra::kable_styling(font_size = 6) ``` ] ] .pull-right[ .small[ <table> <thead> <tr> <th style="text-align:left;"> out </th> <th style="text-align:right;"> AsYouLikeIt </th> <th style="text-align:right;"> HenryV </th> <th style="text-align:right;"> JuliusCaesar </th> <th style="text-align:right;"> TwelfthNight </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> battle </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> fool </td> <td style="text-align:right;"> 36 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 58 </td> </tr> <tr> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 115 </td> <td style="text-align:right;"> 91 </td> <td style="text-align:right;"> 71 </td> <td style="text-align:right;"> 80 </td> </tr> <tr> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 21 </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 15 </td> </tr> </tbody> </table> ] ] --- .midi[ - This is an example of a **term-document matrix**: each row represents a word in the volcabulary and each column represents a document from some collection of documents. ] .small[ <table> <thead> <tr> <th style="text-align:left;"> out </th> <th style="text-align:right;"> AsYouLikeIt </th> <th style="text-align:right;"> HenryV </th> <th style="text-align:right;"> JuliusCaesar </th> <th style="text-align:right;"> TwelfthNight </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> battle </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> fool </td> <td style="text-align:right;"> 36 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 58 </td> </tr> <tr> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 115 </td> <td style="text-align:right;"> 91 </td> <td style="text-align:right;"> 71 </td> <td style="text-align:right;"> 80 </td> </tr> <tr> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 21 </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 15 </td> </tr> </tbody> </table> ] .midi[ - The table above is a small selection from the larger term-document matrix. ] .midi[ - A document is represented as a count vector. If `\(|V|\)` is the size of the vocabulary (e.g., all the words in a document) then each document is a point in `\(|V|\)` dimensional space. ] --- # TF-IDF - Simple frequency isn’t the best measure of association between words. -- - One problem is that raw frequency is very skewed and not very discriminative. -- - The dimension for the word good is not very discriminative between Shakespeare plays; good is simply a frequent word and has roughly equivalent high frequencies in each of the plays. -- - It’s a bit of a paradox. Words that occur nearby frequently (maybe pie nearby cherry) are more important than words that only appear once or twice. Yet words that are too frequent are unimportant. How can we balance these two conflicting constraints? --- ## Term Frequency - term frequency is the frequency of word `\(t\)` in document `\(d\)`. In the `tidytext` package it's computed as: `$$f_{t,d}/\sum_{t^{\prime} \in d}f_{t^{\prime},d}$$` - `\(f_{t,d}\)` is the count of term `\(t\)` in document `\(d\)`. - `\(\sum_{t^{\prime} \in d}f_{t^{\prime},d}\)` is the total number of terms in `\(d\)`. --- The Shakespeare example below assumes that each document only has four words. So, if `\(d=\)` "As you like it" and `\(t=\)` "battle" then term frequency is, 1/(1+36+115+21) = 0.0057803. .small[ <table> <thead> <tr> <th style="text-align:left;"> out </th> <th style="text-align:right;"> AsYouLikeIt </th> <th style="text-align:right;"> HenryV </th> <th style="text-align:right;"> JuliusCaesar </th> <th style="text-align:right;"> TwelfthNight </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> battle </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> fool </td> <td style="text-align:right;"> 36 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 58 </td> </tr> <tr> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 115 </td> <td style="text-align:right;"> 91 </td> <td style="text-align:right;"> 71 </td> <td style="text-align:right;"> 80 </td> </tr> <tr> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 21 </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 15 </td> </tr> </tbody> </table> ] --- ## Inverse Document Frequency - Terms that are limited to a few documents are useful for discriminating those documents from the rest of the collection. - Terms that occur frequently across the entire collection aren’t as helpful. - Let `\(n_{\text{documents}}\)` be the number of documents in the collection, and `\(n_{\text{documents containing term}}\)` be the number of documents containg the term. Inverse document frequency is defined as: `$$idf(\text{term}) = \ln\left(\frac{n_{\text{documents}}}{n_{\text{documents containing term}}} \right).$$` --- ## tf-idf `$$\text{tf-idf}(t,d) = \underbrace{\left(f_{t,d}/\sum_{t^{\prime} \in d}f_{t^{\prime},d}\right)}_{\text {term frequency}} \times \underbrace{idf(\text{t})}_{\text{inverse document frequency}}$$` `\(t\)` is a term and `\(d\)` is a collection of documents. --- ```r tf_idf <- shakespeare_books %>% unnest_tokens(out, text) %>% mutate(out = tolower(out)) %>% filter(out == "battle"|out == "good" | out == "fool"|out == "wit") %>% group_by(book, out) %>% count() %>% * bind_tf_idf(term = out, document = book, n = n) tf_idf %>% knitr::kable() %>% kableExtra::kable_styling(font_size = 9) ``` <table class="table" style="font-size: 9px; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> book </th> <th style="text-align:left;"> out </th> <th style="text-align:right;"> n </th> <th style="text-align:right;"> tf </th> <th style="text-align:right;"> idf </th> <th style="text-align:right;"> tf_idf </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> AsYouLikeIt </td> <td style="text-align:left;"> battle </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0.0057803 </td> <td style="text-align:right;"> 0.6931472 </td> <td style="text-align:right;"> 0.0040066 </td> </tr> <tr> <td style="text-align:left;"> AsYouLikeIt </td> <td style="text-align:left;"> fool </td> <td style="text-align:right;"> 36 </td> <td style="text-align:right;"> 0.2080925 </td> <td style="text-align:right;"> 0.2876821 </td> <td style="text-align:right;"> 0.0598645 </td> </tr> <tr> <td style="text-align:left;"> AsYouLikeIt </td> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 115 </td> <td style="text-align:right;"> 0.6647399 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> AsYouLikeIt </td> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 21 </td> <td style="text-align:right;"> 0.1213873 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> HenryV </td> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 91 </td> <td style="text-align:right;"> 0.9680851 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> HenryV </td> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 0.0319149 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> JuliusCaesar </td> <td style="text-align:left;"> battle </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0.0975610 </td> <td style="text-align:right;"> 0.6931472 </td> <td style="text-align:right;"> 0.0676241 </td> </tr> <tr> <td style="text-align:left;"> JuliusCaesar </td> <td style="text-align:left;"> fool </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0.0121951 </td> <td style="text-align:right;"> 0.2876821 </td> <td style="text-align:right;"> 0.0035083 </td> </tr> <tr> <td style="text-align:left;"> JuliusCaesar </td> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 71 </td> <td style="text-align:right;"> 0.8658537 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> JuliusCaesar </td> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 0.0243902 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> TwelfthNight </td> <td style="text-align:left;"> fool </td> <td style="text-align:right;"> 58 </td> <td style="text-align:right;"> 0.3790850 </td> <td style="text-align:right;"> 0.2876821 </td> <td style="text-align:right;"> 0.1090559 </td> </tr> <tr> <td style="text-align:left;"> TwelfthNight </td> <td style="text-align:left;"> good </td> <td style="text-align:right;"> 80 </td> <td style="text-align:right;"> 0.5228758 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> TwelfthNight </td> <td style="text-align:left;"> wit </td> <td style="text-align:right;"> 15 </td> <td style="text-align:right;"> 0.0980392 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> </tbody> </table> --- .left-code[ .small[ ```r library(gridExtra) p1 <- tf_idf %>% ggplot(aes(out,tf)) + geom_col(fill= "grey", colour = "black") + coord_flip() + facet_wrap(~book, nrow = 4) + ggtitle("Term Frequency") + xlab("Term") + ylab("Term Frequency") + theme_minimal() p2 <- tf_idf %>% ggplot(aes(out,tf_idf)) + geom_col(fill= "grey", colour = "black") + coord_flip() + facet_wrap(~book, nrow = 4) + ggtitle("TF-IDF") + xlab("Term") + ylab("TF-IDF") + theme_minimal() grid.arrange(p1,p2, ncol = 2) ``` ] ] .right-plot[ <img src="workshopslides1_files/figure-html/unnamed-chunk-47-1.png" width="80%" /> ] --- class: center, middle # Questions?